http://www.mymachine.org/cgi-bin/dmoz?context=ccontrol_panel.
Load from file link. Now you should see a screen that looks
like the figure below.
Go to the first, previous, next, last section, table of contents.
The site http://www.dmoz.org/ provides a dump of their catalog data. The format of the dump is a custom XML that looks like RDF but is not really. Since the XML format of dmoz.org and the XML format of Catalog are not compatible, the convert_dmoz is provided to perform the translation. It can be called on the command line to produce a dmoz.rdf file ready for loading with Catalog.
Since the dmoz.org catalog has specific requirements, a specialized version of Catalog is also provided. If you access Catalog using the CGIDIR/dmoz cgi script instead of CGIDIR/Catalog, you will use this specialized version.
We have loaded a version of dmoz.org that contains approximately 400 000 records and around 65 000 categories on a Pentium 350. It leads to a 400Mb MySQL database. It takes about seven hours to load. The response time when navigating the categories is excellent, provided you are using Apache + mod_perl.
The memory used during the load is around 10Mb for the conversion and 10Mb for loading. If you notice that the processes are growing beyond these limits, make sure you are using the XML-Parser version provided on www.senga.org. XML-Parser-2.21 and XML-Parser-2.23 have a known memory leak problem.
In order to load dmoz.org data using Catalog you must follow these steps:
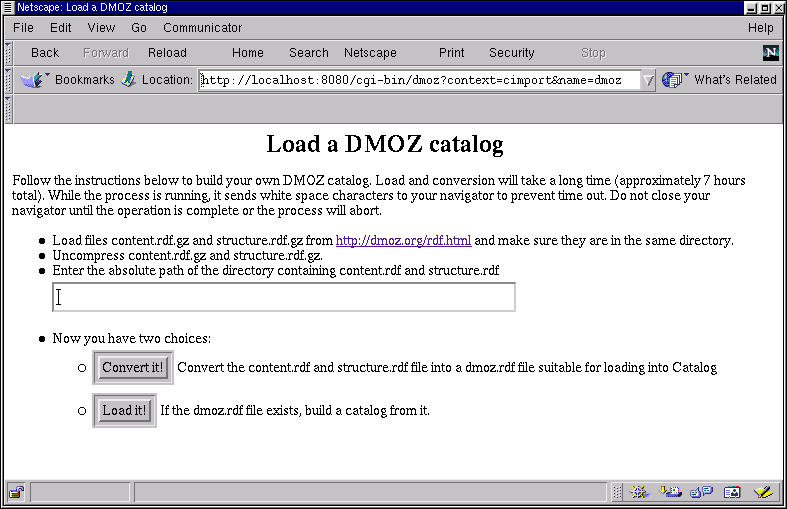
http://www.mymachine.org/cgi-bin/dmoz?context=ccontrol_panel.
Load from file link. Now you should see a screen that looks
like the figure below.
Alternatively you may want to do it using the command line only.
convert_dmoz content.rdf structure.rdf dmoz.rdf
REQUEST_METHOD=GET \ QUERY_STRING="context=cimport_dmoz&path=`pwd`&action=load" \ CGIDIR/dmoz
Go to the first, previous, next, last section, table of contents.